
My Experience Building Simple AI Agents
Everyone's doing it. Or should be. AI Agents are going to change a lot. (#89)


A few weeks ago I decided to build an AI agent. My goal: track all LinkedIn posts that mention “venture studios” and have those posts published in a Google Doc every day. Simple enough, right?
This was partially inspired by watching a video by Ben van Sprundel (Ben AI): This 20+ AI Agent Team Automates ALL Your Work.
Step 1: Ask ChatGPT for help
I started with this prompt in ChatGPT (I’m not a prompt expert):
Here's what I want to do: Run a daily search of LinkedIn posts for any post that has the keywords "venture studio" or "venture studios". I only want posts from the last 24 hours. I want the name of the poster, post content, # of comments, timestamp, date stamp and post URL. Once I have that information I want an agent to summarize each post and put it all in a Google Doc.
ChatGPT gave me a detailed implementation plan.
Sadly, the first step—getting posts out of LinkedIn—was a pain in the ass.
Step 2: Getting Data from LinkedIn
ChatGPT gave me two options for getting the data from LinkedIn:
Option 1: LinkedIn API (Preferred)
Sign up for access to LinkedIn’s API. The v2/posts endpoint allows access to post data based on keywords.
Use a query like keywords=venture studio with a filter for posts from the last 24 hours.
Note: The LinkedIn API has usage limits, so ensure your usage complies with LinkedIn’s developer policies.
Option 2: Web Scraping
If you don’t have API access, you can use tools like PhantomBuster or Apify to scrape LinkedIn search results.
Use search queries "venture studio" and "venture studios".
Apply a filter to fetch only recent posts (last 24 hours).
Warning: Scraping LinkedIn without permission may violate their terms of service. If using this method, take ethical considerations and compliance into account.
I tried using LinkedIn’s API but couldn’t figure it out quickly enough. It wasn’t obvious how to get post data from the API (I’m still not sure you can). Funnily enough, you could query through LinkedIn’s web application easily enough. (search for “venture studio” related posts in the last 24 hours).
I eventually got PhantomBuster to work. It took a few tries and some customer support, but I managed to run the search query and get posts into a CSV file. (BTW, it’s clear to me that “ChatGPT SEO” is a real thing and important. People will use ChatGPT more and more for recommendations and if your company doesn’t show up…🤷🏻)
Step 3: Using Relevance AI
Next, I asked ChatGPT if I could do everything I need through Relevance AI. I wasn’t sure if Relevance AI was the best tool, but I wanted to try it.
This is where things got complicated. 😆
For starters, ChatGPT spat out a ton of Python code for how to do everything, starting with installing the Relevance AI SDK on my computer. I wanted to do things through Relevance AI’s web interface, so I had to ask specifically for those instructions.
Sometimes, ChatGPT makes mistakes (or doesn’t provide clear enough instructions; or I’m just an idiot). Here’s an example:

That all sounds reasonable except I could not find the Dataset option in Relevance AI. I checked if I had the right Relevance AI subscription, upgraded (just in case), but no luck. There's no Dataset option. (There is a Knowledge feature, where you can upload content/data, so maybe that’s what ChatGPT meant?)
I decided to try alternatives to Relevance AI, because it was getting too frustrating. I also contacted support (which was helpful, but wasn’t real-time; and the AI-based support sucked).
Step 4: Try Alternative Options
I tried two alternatives, Make.com and Zapier. Make was mentioned by ChatGPT, so I signed up. Unfortunately they start you with a blank canvas and I had no clue what to do. I prefer to learn by doing (versus reading or watching videos) so I almost instantly gave up. Lesson: Don’t start people off with a blank screen and no clear instructions. Instant fail.
I’ve used Zapier before so I gave it a try. It almost worked, but its looping capabilities are suspect. For example, I got the CSV file uploaded into Zapier and asked it to loop through all the posts to clean them up (from comma delimited CSV into JSON). I know looping is possible, but it got whacky and ended up costing me a ton of credits. I abandoned Zapier and went back to Relevance AI.
Step 5: Agents and Tools in Relevance AI
Relevance AI has a simple prompt for creating an agent:
It’s pretty cool. It outputs the core instructions for an agent, which might look like this:

Each of the things in a gray box (such as “Google Search” or “Interpret website visually”) is a tool. Tools are used by agents to do the job you’ve set out for them. My sense is that tools are meant to be simple (i.e. with minimal steps), but as I dug in, I started using them as workflows.
When the AI first builds the agent’s core instructions it’ll recommend tools that don’t exist, which means you have to build the tools (unless there are template tools you can use).
I wrote some instructions for my agent through the prompt, it recommended creating a few tools and I gave that a try.
Tools are definitely workflows (like Zapier), but again, I think best practice is to have them do a single, discrete thing versus a complex set of tasks in a row. It wasn’t totally clear to me how much logic you should put into the agent versus the tools. So I leaned into getting the workflow correct, through tools, before figuring out how to make an agent work.
Side note: I discovered a specific GPT for Relevance AI (not sure if it was made by them). It was helpful, but often led me to things I couldn’t figure out or resources I couldn’t find in Relevance AI. It (like ChatGPT) seemed very eager to have me run the Relevance AI SDK locally and write Python code; I had to keep telling it I was using the web version of the product.
I went back and forth for hours (and days) with ChatGPT (using the Relevance AI GPT) to figure things out. I gave it instructions and it spat out answers, which I followed (mostly blindly) to see what would happen. My sense: It overcomplicated things quite a bit. For example:
Once I got the CSV file through a GET step, it suggested I convert the CSV file into a JSON. The conversion was easy (there’s a prebuilt step for that).
Then using an LLM step, I had the tool categorize posts and output a new JSON.
I gave up on figuring out how to post into a Google Doc (I couldn’t understand the ChatGPT instructions at all), and decided to push the content to Slack (since there’s a default feature in Relevance AI for doing so). Then I realized that the JSON formatting wasn’t going to work.
So I added another LLM step to clean up the formatting and make it readable. But the markdown that it generated wasn’t the right markdown for Slack, which meant the content pushed to Slack was a mess.
I struggled with all of this for awhile. I nearly gave up when my LLM step for categorization refused to categorize all the posts in the JSON. ChatGPT provided recommendations for debugging by adding additional Python code steps to count the rows before and after categorization. Here’s an example (modified):
# "params" are all the user inputs
# "steps" are all the inputs and outputs from previous steps
# There are several functions prepackaged in this code
# DOCS: https://relevanceai.com/docs/tool/tool-steps/python-code/code-python-helper-functions
# IMPORTANT: Include a "return" statement in your code if you want to use the output in following steps
import pandas as pd
# Path to the uploaded CSV file
csv_file_path = "https://cache1.phantombooster.com/string-goes-here/file-name-here.csv"
# Load the CSV into a DataFrame
df = pd.read_csv(csv_file_path)
# Count the number of rows
row_count = len(df)
# Output the row count
print(f"Number of rows in the CSV: {row_count}")
# Return the row count
return row_countOften when ChatGPT generated code it was wrong. I’d go back and forth with it many times, sharing the errors and asking ChatGPT to fix them. It would try, fail, try again, fail, try again, fail. I’d give up, take another approach. More code. More bugs. Eventually I’d get it to work! And that was just to count the f***ing rows in a JSON file! Sigh. 😢
I also used an LLM step to debug. Here’s an example of the instructions I gave it:

It would count the posts correctly, categorize them and then tell me it categorized all of them. But it didn’t. 😤
I never figured out why the number of posts shrank as I went from the original file through its conversion into JSON and categorization. I tried a couple things:
Changing the model. I was using GPT 4o mini, so I switched to Claude v2.1. It didn’t help (and it consumed a ton of tokens).
I tried adding “Max Tokens” in the settings, thinking the response was being cut off. It wasn’t.
Another step that nearly killed me was trying to convert the JSON to a readable format with the right markdown for Slack. I probably spent a few hours on this with ChatGPT trying to get the code right. I had a Python code step, which ran code like this:
# "params" are all the user inputs
# "steps" are all the inputs and outputs from previous steps
# There are several functions prepackaged in this code
# DOCS: https://relevanceai.com/docs/tool/tool-steps/python-code/code-python-helper-functions
# IMPORTANT: Include a "return" statement in your code if you want to use the output in following steps
import re
def markdown_to_slack(markdown_text):
"""
Converts Markdown-formatted text into Slack-compatible formatting.
Fixes list markers and bold formatting issues.
"""
# Convert bold (**text**) to Slack's *text*
markdown_text = re.sub(r"\*\*(.*?)\*\*", r"*\1*", markdown_text)
# Convert italic (*text*) to Slack's _text_
markdown_text = re.sub(r"(?<!\*)\*(.*?)\*(?!\*)", r"_\1_", markdown_text)
# Convert links [text](url) to Slack's <url|text>
markdown_text = re.sub(r"\[(.*?)\]\((.*?)\)", r"<\2|\1>", markdown_text)
# Ensure each field (e.g., *Name:*) gets a dash (`-`) as a prefix and is bolded
markdown_text = re.sub(r"^(\s*)(\*\w+:\*)", r"- \2", markdown_text, flags=re.M)
# Handle empty fields (e.g., *Name:* [No Data])
markdown_text = re.sub(r"(\*Name:\*)\s+\|", r"\1 [No Data]", markdown_text)
# Return the cleaned text
return markdown_text
# Replace test input with actual post data (formatted as before)
llm_answer = """{{ llm.answer }}"""
# Debug to confirm that llm_answer contains the expected data
print("LLM Answer (Raw Input):", llm_answer)
# Convert the Markdown to Slack-compatible format
slack_text = markdown_to_slack(llm_answer)
# Print the result
print(slack_text)
# Return the result as a JSON object to make it accessible in the workflow
return {"slack_text": slack_text}I never quite got this to work and it was very frustrating. For example, when it sends a Slack message I was hoping it would summarize the post and hyperlink the summary:
Instead it would constantly try to “escape” the URL and spit out something like this:
Post: https://www.linkedin.com/feed/update/urn:li:activity:7294009129663139841%7COlder Solo-Founders Are Killing It.
Eventually, I got fed up and separated the post and URL:
Post: Older Solo-Founders Are Killing It.
URL: https://www.linkedin.com/feed/update/urn:li:activity:7294009129663139841
This is a completely reasonable solution, but I wanted it to look cleaner in Slack.
Step 6: Simplifying Everything
Eventually, I ended up with a tool (debugging steps included) that was too complicated. I decided to take a simpler approach. This resulted in the tool going from ~8-10 steps to 3.
Get the PhantomBuster results — This stayed the same. The Relevance AI tool has to get the generated CSV file.
Rely on the LLM to work its magic — I wrote a fairly comprehensive prompt (although it still took fiddling with) to do everything I needed with GPT 4o mini:
Convert the following csv file into a more human-readable format. The csv contains posts that we want to separate out properly. Each post starts with the postURL.
INPUT:
{{api.response_body}}
INSTRUCTIONS:
* Find each {{postURL}} - that's the start of a new posts that we want separated out into a readable format
* Also get the profileURL, companyName, postTimestamp, fullName, textContent from the csv
* postURLs should only be used 1 time, and it's important that you put the right postURL with the right related content
OUTPUT: For each post, display the following exactly as it is written below, maintaining the formatting presented:
* *Post:* [1 sentence highlight of the post]
* *URL:* <postURL>
* *Name:* <profileURL|[fullName]>
* *Company:* companyName
* *Date:* postTimestamp [format postTimestamp as mmmm, dd, yyyy]
* *Category:* category [use one of the following categories:
- Announcements [any news from a venture studio about raising capital, launching a new startup or something else]
- Team [any news about jobs, careers or specific team members of a venture studio such as a job promotion]
- Funding [any news about funding for a venture studio or one of their portfolio companies]
- Insights [any thought leadership or opinion posts about venture studios, best practices, etc.]
- Events [any post about events or webinars]
- Partnerships [any post about a partnership or collaboration that a venture studio is involved in, which could be with a corporate partner, venture capitalist, government agency or someone else]
- General Discussion [any post that speaks about venture studios, their merits, is a question related to a venture studio or something similar]
- Other [a miscellaneous category for any posts that don't fit one of the other categories]
NOTE: Each post in the csv file should only be categorized once.]
* *Summary:* textContent [a brief summary]
- Remove posts in the Events category
- Remove posts in the Team category
- List the remaining posts
Send the output to Slack:
*Here's the latest venture studio news:*
{{llm_3.answer}}
This works reasonably well. But it’s not perfect. The LLM reinterprets things a little differently each time. For example, it recently decided that “companyName” would pull from the person’s headline instead:
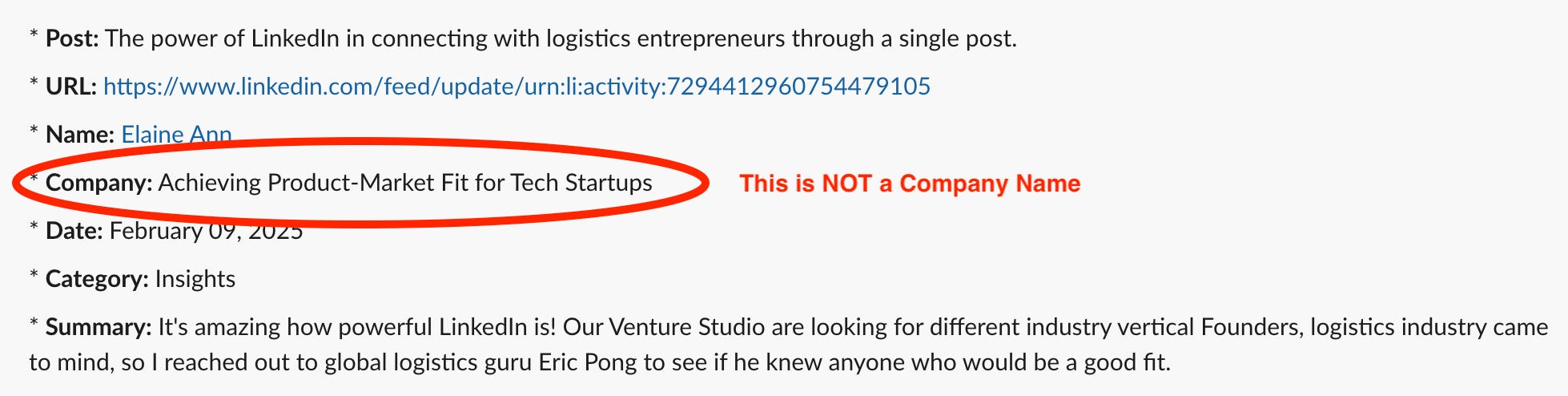
Sometimes it gets the URL or name wrong. And it doesn’t categorize as well as I’d like—the output still contains things I’m not interested in. At least the Relevance AI tool itself is simple and I can keep mucking with the prompting to see if it provides more accurate results.
Step 7: Building the Actual Agent
At this point I have a tool with 3 steps that gives me what I want (sort of). The next thing I needed to do was create an agent to run the tool. In this case the agent is pretty simple, because all I want it to do is run the tool exactly as it’s designed. This isn’t quite what agents are for—they’re not meant to be dumb triggers—but I just wanted to get it working.
Here’s Scout, the LinkedIn Insights Analyzer:

The instructions are very clear — just run “Classify LinkedIn Post 2” exactly as it’s designed. That’s it.
If you dig into Relevance AI’s agent examples / marketplace you’ll see much more complex agents. Many are designed to “think” and make decisions. Scout is not.
Step 8: Trigger the Agent
Agents don’t do anything without a trigger. You have to prompt them to take action. You can give an agent instructions through Relevance AI manually, but I wanted the process to run every night.
I finally figured out how to setup a trigger using email. IMO, this is a hack, but it works:
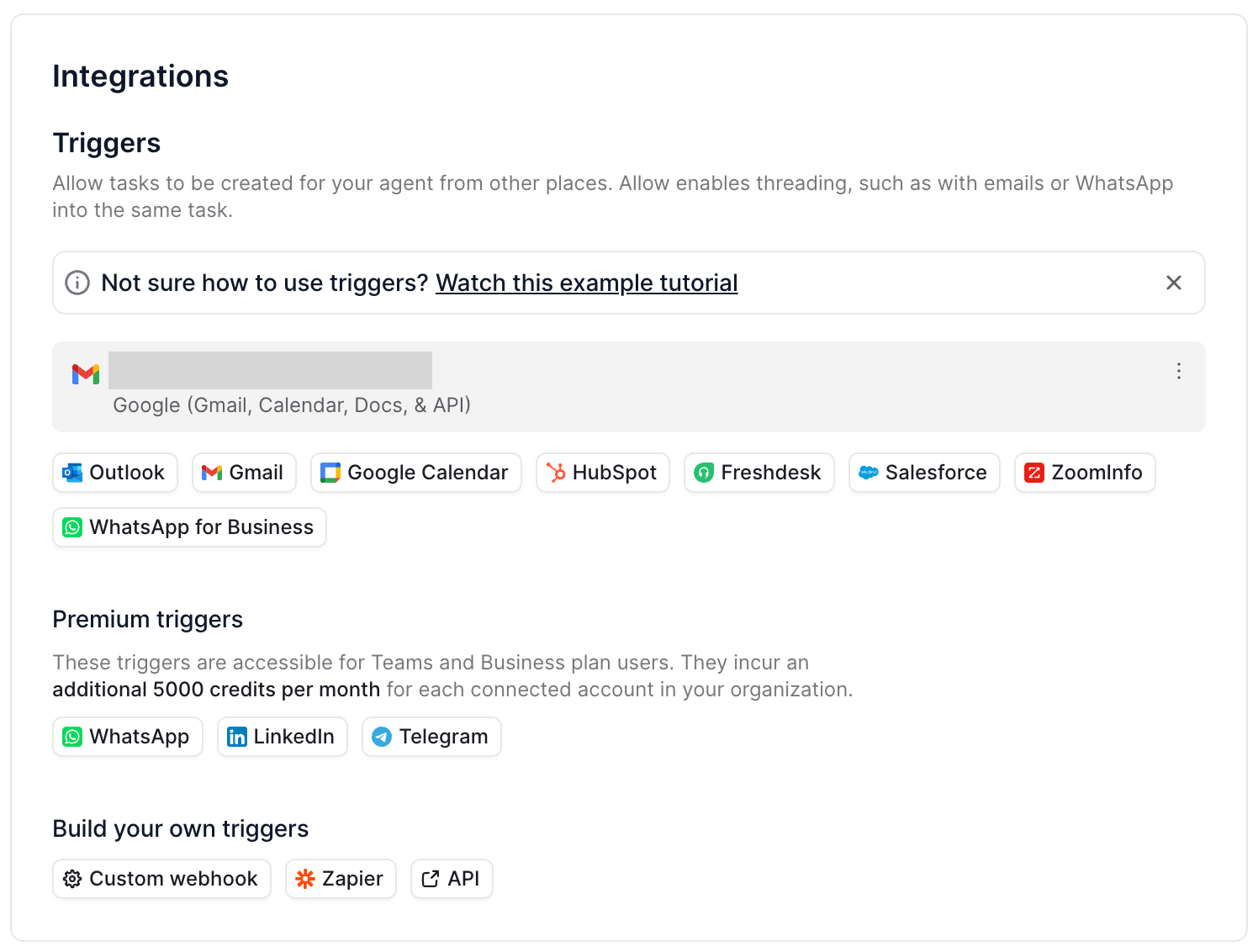
I created a new email address (hidden so people don’t spam it! 😂).
I setup the agent to run when the new inbox gets an email with a specific subject line.
I then realized that Gmail doesn’t let you send recurring email; so I found a tool (Right Inbox) that adds the recurring send functionality.
I created a daily recurring email to go from my work email to the new inbox.
Every night at 7:30pm, an email is automatically sent to the new inbox, which then triggers the agent into action. The agent runs its instructions and I receive a Slack message with LinkedIn posts over the last 24 hours that reference venture studios. Phew. 🥳
Summary: Agents Aren’t Quite Ready for Primetime, But…
This took me a lot longer than I would have liked. It’s janky at best. It doesn’t work perfectly. But it does work.
It would probably be faster if I did the LinkedIn search manually every day, but it was still worth building the agent.
I’ve since built a second agent that takes Focused Chaos posts and writes 3 LinkedIn posts in my voice (we’ll see if it works after this post is published!) I actually don’t know how accurate it is at using my voice, but I used Relevance AI’s Knowledge feature to upload about 100 of my LinkedIn posts as a reference. I also setup another email trigger.
Agents are very cool. I’m still stuck in the mindset of “robust workflows that are followed dumbly”, but I see the potential for “smart agents” that adjust to inputs, reason/think and provide insightful recommendations/outputs. I haven’t gotten there yet, but I will.
A few challenges:
Stitching everything together, across different services, is tough.
The outputs are inconsistent.
It feels like everything is held together with chewing gum and tape. Everything is brittle.
If you don’t understand code, it’s tougher.
I’m waiting for a world where I can use voice as an input, tell Relevance AI or some other tool what I want and it just does it all (especially integrations between apps/services). We’re probably not too far off.
Sam Altman said, “We’re going to see 10-person companies with billion-dollar valuations pretty soon…in my little group chat with my tech CEO friends there’s this betting pool for the first year there is a one-person billion-dollar company, which would’ve been unimaginable without AI. And now [it] will happen.”
I believe him.
If you’re a startup CEO or running a department in a startup or big company you have an obligation to explore how AI agents can automate and streamline processes. If you don’t, you’ll get left behind by those that do.
A lot of people say that AI agents won’t replace people, they’ll augment them. Here’s a great Reddit discussion started by someone using OpenAI’s Operator. His conclusion, “it won’t replace jobs.” I don’t know if Operator will replace jobs, but AI agents will. AI will augment and replace. Some humans are going to lose their jobs, let’s not be naive about this.
The Implications for Venture Studios
I’m now looking at every process at Highline Beta and thinking, “Can AI agents speed this up? Can AI agents improve this?” I’m not married to any specific tool (because the tools change), I’m focused on rethinking how we work, what we work on, and what can be augmented and improved.
As a venture studio, I’m deeply invested in the idea of automating and enhancing everything we do for the startups we create.
How can we speed up the validation process (research, prototyping, GTM channel testing, etc.)?
How can we better equip startups with agents / tools / best practices for automating their workflows and tasks?
How can we give startups “AI agents in a box” for marketing, sales, customer success, etc. when they leave the venture studio?
A venture studio’s job is to repeatably build and fund startups (and generate returns). The key word in that sentence is “repeatably.” AI agents unlock some of that repeatability, with a certain degree of scale, without the need for a big team. Since venture studios often have a complicated business model (i.e. they struggle to generate sufficient revenue/capital to cover costs), anything that keeps operating expenses down is worth exploring.
Do I think AI can build startups on its own without humans? No. Perhaps this is my bias, but I still believe in human creativity, dot connecting, experience and gut instincts. Parts of the process require a human touch, and the AI tooling today isn’t robust enough to go through the whole process on its own.
Here’s a great example from David Arnoux. He’s strung together a bunch of tools to help him validate new businesses. David uses tools such as Synthetic Users to conduct interviews. It’s not bad, but it’s not a replacement for interviewing real people. We’ve found it helpful as a quick “sniff test” around a problem space or to help us refine our interview guide, but we’ll always reach out to real people and conduct interviews. Other tools for landing page creation, ad testing, prototype building work are decent, but they still need the deft touch of a skilled person.
I’ve encouraged the whole team at Highline Beta to test new tools, build their own agents and experiment actively. Experimentation is truly the key, especially because everything is still messy. The mindset has to shift from, “That’s how we’ve always done it,” to, “Maybe AI agents make this better?” Sometimes the answer is “no” (I’m not an AI agent zealot!) but you need to ask. Things are changing. Fast. Luckily, it’s still early days—you have time to jump in and figure things out.
If I can build an AI agent (even a basic workflow one) anyone can. That’s perhaps the biggest lesson out of the whole experience. Anyone can build an agent. That’s crazy, crazy powerful. It’s not as easy as it should be and it can be super frustrating, but it’s possible. You don’t need to know Python (although learn how to read the basic code!) You don’t need to be an AI expert (although understand how it works). Just try it. Identify a use case, pick a few tools and build an AI agent. Then let me know how it goes and how I can improve… 🤣
Good luck!
Your article about building AI agents really hit home! While exploring similar solutions, I discovered BoodleBox's custom bot builder (https://boodlebox.ai/blog/support/creating-custom-bots/), and it was such a relief compared to the complex journey you described. I found their platform incredibly straightforward with no coding or complex integrations needed. I was able to jump right in and create my own bot.