
Lean Analytics, Reconsidered
The frameworks survive. Many of the specific metrics need a rewrite, some don't apply at all, and new metrics are emerging quickly.

People often ask me how Lean Analytics changes in an AI world. It’s something I’m thinking about a lot, because things are happening so quickly.
My co-author, Alistair Croll and I have been jamming on this too. He’s thinking way further ahead than me (as is always the case!) but we’re seeing the same things: the cost of building has collapsed, models drift under your feet, and your “users” might not be human at all.
The short version: the core Lean Analytics frameworks survive. Many of the specific metrics you were taught to obsess over need a rewrite. Some have been replaced entirely.
This post is about how to tell them apart. Fair warning, it’s a long one. We’re going to cover what still works (fast), what’s changing at the product metric level (in detail), what’s changing at the business model level (where some of the real damage is happening), and what’s coming next (more speculative, but important).
A quick primer, in case you haven’t read Lean Analytics (the book)
If you’ve read Lean Analytics, skip this section (or skim it). You can probably ask ChatGPT or Claude for a synopsis. You can always get the book, too. 😉
Here’s enough to follow along.
Lean Analytics has four ideas worth anchoring on:
1. Know your stage
In Lean Analytics, we proposed 5 stages that all businesses go through: Empathy → Stickiness → Virality → Revenue → Scale.

Here are a couple primers:
At each stage there are key metrics to track. A lot of founders lie to themselves about the stage they’re at, eager to hit hockey stick growth before laying down a solid foundation. That’s very true in today’s rush to build the next AI darling.
2. Know your business model
We defined six archetypes: SaaS, e-commerce, two-sided marketplace, user-generated content/community, mobile app, and media. These are outdated, but the principle of knowing how your business works is critical.
When you’ve mapped your business it helps determine which metrics to track. Here’s a classic example from the book:
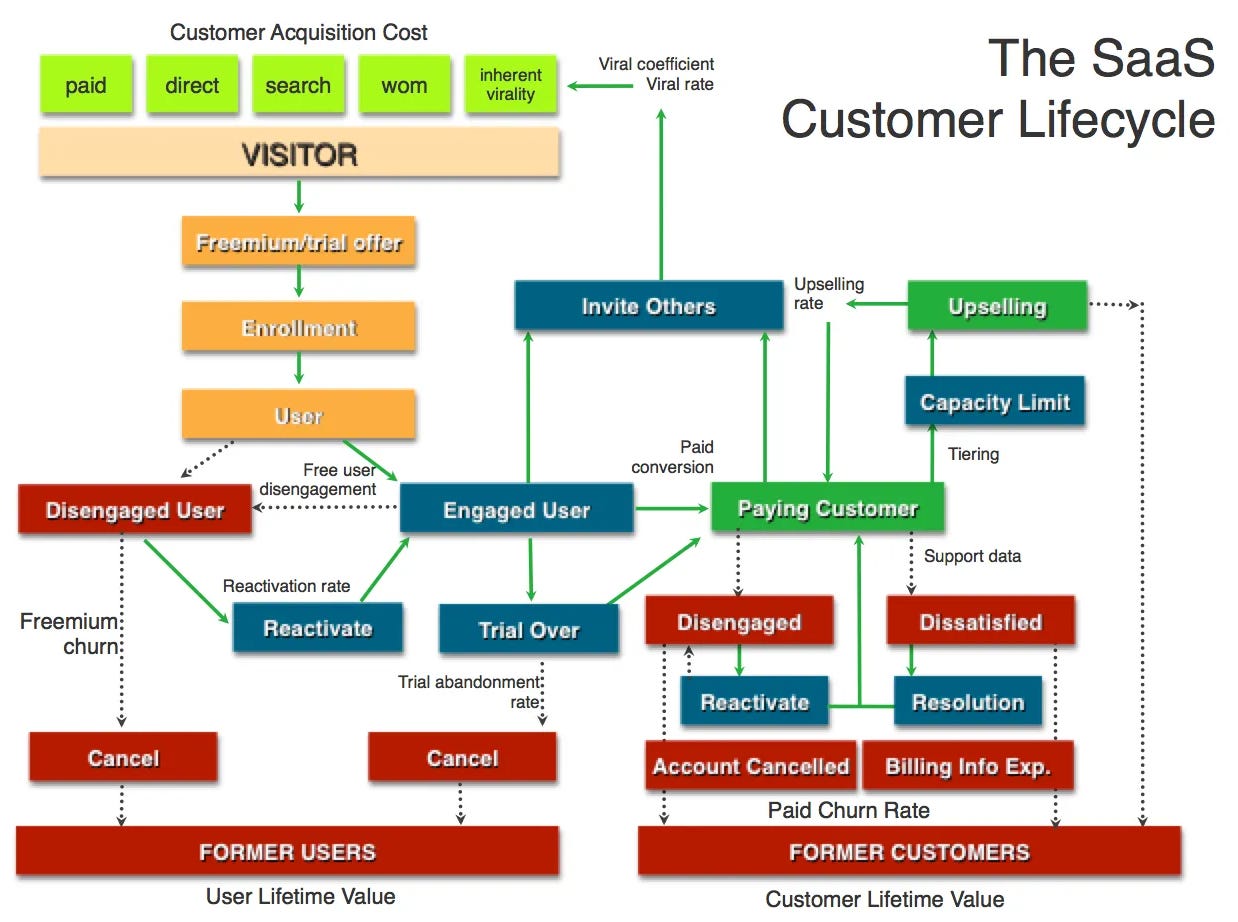
You can dig into the concept of mapping your business (and the business model) through a few posts:
The Importance of Business Models to Building Great Products
Your Startup is a System You Can Map to Identify Problems, Align the Team & Win
3. Pick the One Metric That Matters (OMTM)
At any stage, for any business model, there’s a single metric you should be focused on. This is the concept of the One Metric That Matters.
You can’t fix everything at the same time. The OMTM helps you identify what to work on and the right way to measure it.
Here are some relevant posts:
4. Use lines in the sand
Benchmarks tell you when you’ve earned the right to move on. We called them “lines in the sand” because they’re not writ in stone. Thankfully there’s a lot of data out there on targets for specific metrics, although with AI and agentic products, the metrics and targets are moving quickly.
Here’s a post with more information on benchmarks: 4 Steps to Building Super Stick Products Leveraging Your Best Users
None of these principles change in an AI era
Although Lean Analytics was written in 2013, the core principles are sound. But the businesses being built today are significantly different. AI changes user interfaces, pricing models, profit margins, and much more. AI-first and agentic products are used differently. Expectations for value creation change. Connectivity between platforms changes.
Example: The five stages don’t disappear. They get a question mark attached to each one.
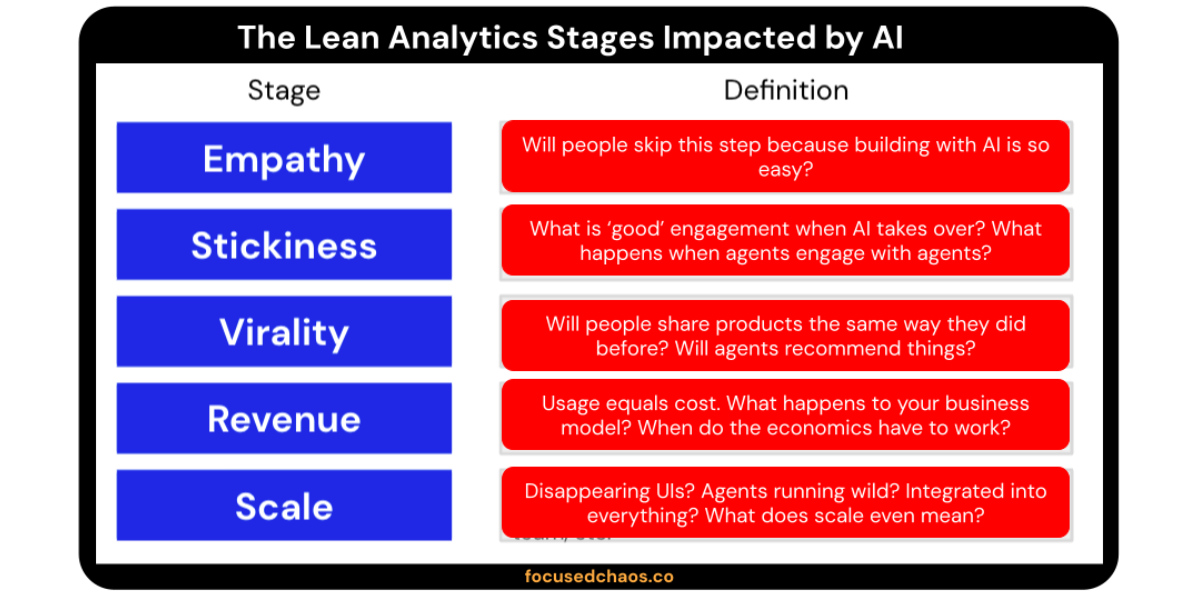
We need to integrate new metrics in with old ones to define each Lean Analytics stage. We need new metrics to help evaluate whether our business model is working. We still need to measure what’s going on, but we’re changing what and how.
Let’s start with product metrics.
Product metrics: six shifts that matter
Shift 1: Time to value collapses
Traditional SaaS had straightforward onboarding flows. Users signed up, went through a few steps, saw value and hopefully returned. It was rarely immediate, and Time to Value (TTV) wasn’t even a priority for many companies.
In 2024 I ran a study on TTV and the results were fascinating. Here’s one example:
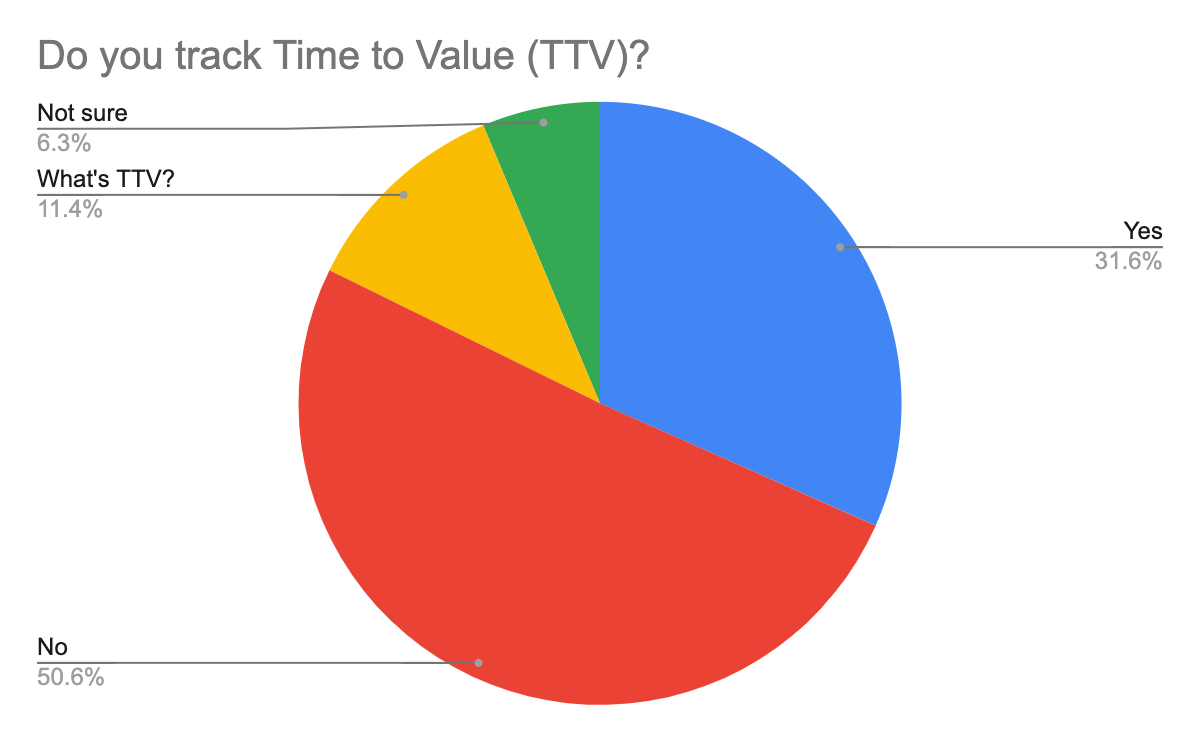
How should you think about TTV value for AI products?
My experience: People are willing to try but fickle.
As people get more comfortable with AI, there’s a recognition that things are a touch experimental. They’re willing to test things out, but to an extent.
If they’re not convinced that the output quality is high enough they’ll move on. Fast. And the expectation bar is going up; people are aware of the hype so they expect your AI product to blow them away.
This isn’t just about chat products. A user drops in a messy document and expects a polished proposal back. Uploads a spreadsheet and expects clean analysis. Sketches a wireframe and expects a working UI. Hands over a contract and expects an instant review. The input method varies. The expectation is constant: fast, high-quality output, first try (or very shortly thereafter).
There’s a flip side that’s interesting. Time to competency has collapsed too. Non-technical users can now generate expert-level outputs without the training curve that used to gate them. Your activation curve used to be a learning curve. Now it’s an interaction or two.
That’s a real Lean Analytics shift. What used to be a multi-week journey to competency is now a single input away. The instrumentation has to change to match.
Shrinking time to competency is a good thing. But it may have a negative impact on business models (which I’ll focus on later). If one person can now do the work of three because AI fills in the expertise gap, you don’t need to onboard everyone in the company. That hits your seat counts, your expansion revenue, and your ACV curves. Happy users, fewer seats. That tension starts right here in Shift 1, and it ripples through everything downstream.
What to measure: time to first useful output, and the percentage of users who get a useful result on attempt #1, regardless of whether attempt #1 is a prompt, an upload, or a sketch.
Shift 2: Activation isn’t deterministic anymore
In traditional SaaS, activation was a deterministic event. If the user completed a set of steps (connect your data, invite a teammate, create a project), they hit a predictable output. You could instrument the funnel because A + B + C reliably produced D. I wrote about this with Ben Williams, in the context of early PLG metrics, and most of those metrics assumed that deterministic relationship.
AI breaks that assumption.
In an AI product, a user can complete every step of your activation funnel and still get a mediocre output. They set up their account. Connect their data. Upload the document. Hit run. And the result is... meh. Your dashboard shows them as activated. They are not.
Activation isn’t a binary gate anymore. It’s a quality-weighted event.
This matters because everything in product is a loop. Nir Eyal’s Hooked gave us the dominant mental model for how product habits form: trigger, action, variable reward, investment. Every trip around the loop deepens the habit. That framework still applies in an AI era, but with one critical caveat that breaks a lot of the math underneath it.
In the classic Hooked model, the “action” is deterministic. User takes the action, a reward follows (variable in magnitude, but reliably present). AI loops introduce variance on both sides of the action. Users will stretch and test the edges of what you’ve scoped, prompting or asking for things you never designed the product to do. The outputs will range in quality. Two sources of variance in a single loop is a genuinely harder thing to instrument, and the old retention math wasn’t built for it.
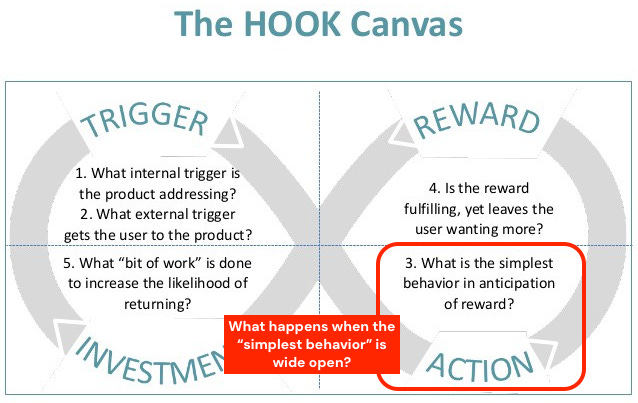
This doesn’t mean activation has to collapse to a single prompt. Compound multi-step activation can still work beautifully in AI products, and often works better than one-shot activation when the setup actually improves outputs. Connecting context, uploading reference material, configuring templates, training the tool on your voice. More setup can equal higher first-run quality, which is exactly what you want. The shift isn’t “activation got shorter.” The shift is that completing the steps doesn’t guarantee the user got value.
What to measure: the old funnel-completion metrics still apply (for now), but pair them with the attempt #1 quality signal from Shift 1. The funnel tells you the user finished the steps. The quality signal tells you whether finishing the steps actually produced value. You need both, and your activation dashboard has to show them side by side.
Shift 3: Engagement is directional (and the axis isn’t product type)
Traditional product wisdom: more time in product = good. Longer sessions. Higher DAU. Deeper feature usage. Session length went on every investor deck.
AI flips the question. The right frame isn’t whether engagement is going up or down. The right frame is more fundamental: what is the user’s time being spent on?
Time spent struggling (regenerating, re-prompting, tweaking inputs to try to get a useful output) = bad engagement, every single time. High regenerate rate, long sessions with no copy or ship event, users abandoning mid-flow. This is failure dressed up as engagement, and it will flatter your dashboard while your product is silently dying.
Time spent with AI doing the work on users’ behalf (spreadsheet being manipulated, proposal being generated, document being reviewed, emails being drafted) = good engagement, potentially very high. The minutes represent AI labor, not user friction. A user whose spreadsheet is being restructured by AI for 20 minutes is getting real value. That engagement number is a feature, not a problem.
Time spent exploring or creating (brainstorming, ideating, iterating on a design or draft) = good engagement. Traditional intuition holds here.
Zero user time, task completed = ideal for agent and automation products. The best outcome is invisible.
Stop asking “is engagement up or down?” Start asking “what is the time being used for?” That’s the PM question now, and most dashboards aren’t set up to answer it.

GitHub Copilot reports percentage of suggestions accepted as a core metric, hovering around 27-30% industry-wide according to published research. That’s a KPI that literally didn’t exist in traditional SaaS. It’s a direct measure of “was the AI’s work useful?” rather than “did the user stick around?” Huge difference.
Shift 4: Stickiness becomes about flow, not walls
Traditional stickiness was a frequency game: DAU/MAU, return visits, habit loops. Andrew Chen wrote a well-known piece years ago about where DAU/MAU breaks down: episodic-but-high-value products, weekly-rhythm tools, anything that doesn’t fit a daily habit pattern. AI doesn’t kill DAU/MAU. It amplifies the limits Andrew was already calling out.
Two things are happening at once.
First, users expect to do more diverse tasks with an AI product than they did with the linear SaaS tool it replaced. “Surely I can do more with this AI than the single-function tool, right?” is becoming the default customer mindset. That’s a real opportunity. PMs should be actively mining what users are prompting, uploading, and asking for beyond the current scope of the product. Task diversity per user is a growth vector that didn’t exist before, and the signal for where to expand your product is sitting in your prompt logs and your interaction data right now.
Second, sticky AI products are less about walls that keep users in and more about being in the flow of their work. Trace Cohen recently wrote a piece called “Moats are dead. Long live canals.” that captures this well. He wrote: “moats scale through exclusion, canals scale through throughput.”
Stickiness in an AI era looks a lot more like canal thinking. You’re indispensable because of throughput and embeddedness, not captive because of switching cost. “Routes,” as Trace puts it, “tend to outlast empires.”
What to measure: DAU/MAU still matters as a baseline (especially while humans are in the loop), but pair it with metrics that actually capture flow:
Task diversity per user. Are users stretching your product into use cases you didn’t originally scope?
Integration depth. How many of the user’s tools and data sources are connected to your product? Each connection is a canal.
Trigger diversity. What brings users back? One trigger or many? Multiple entry points means you’re plugged into multiple parts of their workflow.
Workflow chaining. Does your product hand off to other tools, or receive handoffs from them? Being a node in a multi-step process is the literal definition of being “in the flow.”
When humans stop becoming the primary user, classic DAU/MAU will become problematic.
Don’t be a tiny canal
Stickiness as flow has a failure mode. Being “in the flow” can mean being a small canal between two big rivers, useful today but vulnerable to being widened, narrowed, or rerouted by whoever owns either bank. Today you’re indispensable. Tomorrow the tool upstream ships an AI feature and absorbs your slice.
The defensive move is to eat more of the chain. Legacy moat software is fat, slow, expensive, and not AI-native. The opportunity isn’t to fit neatly between two of those tools. It’s to replace them.
Claude Code didn't just sit alongside your IDE. It replaced enough of the editor, enough of Stack Overflow, and enough of the actual work that developers used to do by hand to become a different shape of product. That's the model.
So add one more metric to the four above: replacement breadth. How many adjacent tools, subscriptions, or manual processes did your customer drop when they adopted you? If the answer is zero, you’re still a tiny canal that can be rerouted around. If the answer is meaningful, you’re becoming the route everything else flows through.
Shift 5: Quality is a first-class metric now
We’re circling back. Shift 2 (activation is a quality-weighted event) and this shift share a root cause: AI outputs are probabilistic, not deterministic. That single change cascades through every metric you inherited from the SaaS playbook. Activation is one place it shows up. Ongoing product quality is the other, and that’s what this shift is about.
Traditional: the feature works, or it doesn’t. You ship it. You instrument it. You move on.
AI reality: outputs are a distribution, not a property.
An 80%-good product and a 95%-good product feel like completely different products to users. That gap matters more than any other gap in your funnel. Quality isn’t something you ship once. It’s something you watch like retention.
Klarna is the cautionary tale. They went big on AI-only customer support in 2024, claiming the AI did the work of 700 agents. By mid-2025 the CEO publicly walked it back and started hiring humans again.

There’s a second piece most teams aren’t tracking well enough: brittleness. Your quality depends on models you don’t own, integrations you barely control, and prompts that can silently regress when an upstream provider updates something. Quality can drop without anyone on your team touching the code. That’s a new risk category, and it doesn’t fit anywhere on a traditional dashboard.
The defense is to measure models against each other on your actual prompts. If you’re using more than one model across your product (and most teams are, or will be), each one has its own quality distribution and each can shift independently. Run the same evals across every model you touch and watch the gaps. When one provider regresses, you’ll see it. When another improves, you’ll see that too. Your model is now a vendor you have to actively manage, not a dependency you can set and forget.
What to measure starts with the basics: thumbs-up rate and regenerate rate as your core signals. Regenerate rate showed up in Shift 3 as a struggle indicator. Here it’s the inverse: same number, different question being asked.
Layer on top of that: eval harness scores tracked over time, the way you’d track retention. Run those evals across every model you use, not just one, so you can spot regressions and improvements as they happen.
And finally: quality distribution by cohort. New users experience a different product than power users do. They don’t know how to engage yet. The tool is worse for them by default, and most teams aren’t measuring that gap.
Sidebar: Alistair on why evals are the new MVP
My Lean Analytics co-author Alistair Croll recently wrote a piece I think every PM should read: “The feedback loop is the product.”
His core argument lines up exactly with this shift. In the Lean Startup era, the MVP was the smallest experiment that tested your riskiest assumption. In an AI era, your riskiest assumption is no longer “can the model do this?” (it can). It’s “does our system behave correctly in the situations that matter most to our users?”
He writes: “The eval suite IS the MVP: the smallest set of behaviors whose improvement you can automate and measure.”
If you’re building AI products and you don’t have an eval harness, you don’t have a product. You have vibes. Go read the post. It’s the clearest explanation of evals-as-management-tool I’ve seen.
Shift 6: Trust and comfort with AI are leading indicators
This wasn’t in the Lean Analytics book, because it didn’t need to be. Tech savviness has always mattered, but it’s never had the range it has now. With a traditional SaaS tool, if a user can click buttons and read labels, they can use the product. With AI, comfort with the technology itself is a variable, and it shapes every downstream metric you care about.
The macro picture is clear. Gallup’s February 2026 study of 23,717 US employees found that what separates AI adopters from holdouts isn’t access to the tools. It’s whether employees see AI as useful, ethical, and a fit for their workflow. Non-users tend to question whether AI is relevant to their role at all. Infrequent users see some potential value but get held back by practical concerns and risk.
Stanford’s 2026 AI Index Report shows global adoption at 58% of employees but the US trailing at 28.3%, far behind Singapore at 61% and the UAE at 54%. The same product can sit on top of dramatically different user populations, and most teams aren’t measuring that.
In a B2B context, my hypothesis is you’ll see meaningfully different activation, stickiness, and task diversity curves between AI-native users and AI-hesitant ones. Same product, same plan, same role, different behavior. The AI-native user stretches the tool, prompts it in ways you didn’t design for, and gets more value per session. The AI-hesitant user is cautious, underuses the tool, and quietly concludes that “this isn’t for me” even when the product is working correctly. If you measure them as one cohort, your averages will hide the real story.
In a B2C context, the stakes get more intimate. Products for companionship, mental health support, friendship, and emotional wellness are now a real category. Stanford’s data shows 52% of respondents globally are excited about AI for companionship, with that number climbing past 80% in places like Singapore and Indonesia. Comfort with an AI in those contexts is the core product question. Value creation is literally measured through the user’s willingness to keep showing up, keep talking, and keep engaging emotionally with something that isn’t human. That’s a very different measurement frame than “did they complete the task?”
Trust also isn’t one thing. It’s at least four things, and they move independently:
Trust in the output: Is this correct? Is this useful?
Trust in data handling: Where does my prompt go? Who sees it?
Trust in security: Can this be exploited or leaked?
Trust in reliability: Will this embarrass me if I rely on it?
I don’t know of teams doing rigorous AI-comfort cohort segmentation in their own product analytics yet. But the variance exists, the tools to measure it exist, and it make sense to do. A single onboarding question (”How often do you use AI in your daily work?”) plus behavioral signals you’re likely already capturing (prompt complexity, regenerate rate, time-to-advanced-feature-use) is enough to build a working cohort view. Run your existing activation, retention, and trust metrics through that lens and you’ll likely see gaps that aggregate dashboards are hiding.
What to measure:
Adoption and activation curves segmented by AI-comfort cohort, not just role or plan.
Accept rate, which we saw in Shift 3 as a measure of “was the AI’s work useful?”, becomes especially revealing when sliced by AI-comfort cohort. How quickly does trust build for AI-native users versus AI-hesitant ones? The slope of the curve, more than the absolute number, tells you whether your product is earning trust or losing it.
Override rate, meaning how often the user rewrites, edits, or redoes the AI’s output. A falling override rate is a rising trust signal.
For emotionally intimate B2C products: session depth, return rate to sensitive features, qualitative tone of interactions.
Signals of data/security concern: feature opt-outs, support tickets asking “where does this go?”, usage that avoids sensitive inputs.
Trust and comfort with AI aren’t soft, squishy, unmeasurable things. They leave real signals in your data. Instrument them the same way you’d instrument retention, because in an AI era they effectively are retention.
Business model metrics: three key shifts
Product metrics change. The bigger shock is what AI is doing to business models.
Picture the scene. Your AI feature launches. Engagement is 10x any other feature in your product. Your CEO is ecstatic. You’re in every all-hands slide for a month.
Six months later, finance review: gross margin has collapsed, your power users cost more than they pay, and your best engagement metric is the one strangling your P&L.
This is happening quietly in products everywhere.

Shift 1: Cost-per-successful-task is your new CAC math
Traditional SaaS: CAC, LTV, and gross margin were relatively stable per customer. Scale made things cheaper, not more expensive. Marginal cost of adding a user was close to zero.
AI reality: your power users literally cost you money.
Tokens are variable cost. Flat-rate subscription plus a heavy user equals negative margin per account. SaaS LTV curves don’t hold. The more someone uses your product, the worse your unit economics get, which is the exact inverse of what you want.
What to measure:
Gross margin per active user. Not per paying user. Per active user. Big difference.
Cost-per-successful-task
Model cost as % of revenue
Marginal cost of power users vs. marginal revenue from them
Intercom’s Fin is a great example of getting this right. They didn’t price per seat. They priced at $0.99 per successful resolution. You only pay when Fin actually solves the issue. That’s outcome-based pricing, and it’s mathematically honest about what AI products actually cost to run. ElevenLabs went usage-based from day one. Anthropic and OpenAI have both publicly wrestled with consumer subscription economics.
If your pricing and metrics don’t reflect variable compute cost, you’re flying blind.
(I wrote more about how business models shape which metrics matter a while back. The core argument holds, the cost structure is what’s new.)
Shift 2: Pricing is a product decision now
Usage-based and outcome-based pricing are still early. Hybrid models (low monthly fee plus usage, with overage) are probably where most AI products eventually land.
Here’s what matters for PMs: pricing decisions are product decisions now, not just finance decisions. The pricing model tells the user what success looks like. It has to match the unit economics underneath. Get that wrong and you’ll either burn margin or cap your growth. Sometimes both.
Think about the difference between “unlimited AI queries for $20/month” and “$0.99 per successful outcome.” Those aren’t just two pricing models. They’re two completely different products from the user’s perspective. The first says “experiment freely, we’ll eat the cost of your learning.” The second says “we only win when you win, and you have to think about what winning means.” Both can work. Neither is neutral.
This is a real shift, because most PMs haven’t had to think deeply about pricing. It was finance’s problem, or the CEO’s problem, or the “we’ll figure it out when we need to” problem. That’s changing fast, and AI-native PMs need to treat pricing as a core part of product design.
Side note: As I build AI tools for Highline Beta (we’re releasing things soon!) I’ve spent a lot of time instrumenting the tools to track AI usage and calculate cost. I’m sure there are tools that do this for you, but I wanted to understand how to do it: learning through building.
It’s interesting to see what actions (features) drive cost, and then determine if they drive commensurate value, and then figure out how to price everything.
You may have AI features in your product that are expensive but don’t create a ton of user value, which can easily kill everything for you. Adding SaaS features was typically cheap (i.e., new features don’t cost a ton to run), which simply isn’t true for AI features.
Shift 3: Experimentation isn’t a vanity metric anymore
Experiment count used to feel like a vanity metric. In an AI era, I think it’s mission critical. And it’s earned that promotion through a specific mechanic that didn’t exist before.
AI-enabled product building lets you release way more, way faster. The cost of shipping a feature has collapsed. That sounds like an unambiguous win, and it isn’t.
If you’re shipping faster but not running real experiments, you’re vibe-stuffing your product (as far as I know, I just invented this term!)

You’re adding features because you can, not because you have evidence they’ll create value. Most of those features won’t. Some will be ignored. Some will be used in ways you didn’t anticipate and couldn’t measure. The product gets bloated, the codebase gets bloated, the cognitive load on users goes up.
On top of that, every AI-powered feature you ship has a cost attached to its use. Not a one-time build cost, an ongoing per-call cost. Inference isn’t free. So the bloat from vibe-stuffing isn’t just clutter, it’s a tax that compounds with usage. You’re paying tokens every time someone touches a feature you didn’t have evidence for. The more it gets used, the more it costs, and you don’t even know if it’s creating value.
That’s a uniquely bad outcome. Slow, expensive, and unproven, all at once. Pre-AI product bloat was annoying. AI-era product bloat is a margin killer.
Strong experimentation is the only defense, and Lean Analytics goes up in value here, not down. The discipline of picking a metric, writing a hypothesis, pressure-testing it, and deciding what to do next is the difference between a team that’s learning and a team that’s just shipping. The Lean Analytics Cycle was built for exactly this, and it has never been more relevant.
A useful filter: for every experiment, write down the hypothesis and the decision criteria before you ship. If you can’t do that, you’re not running an experiment. You’re running a release. Both have their place, but don’t confuse them.
What to measure: experiments-per-quarter as a real metric, not a vanity one. Hypotheses written down before launch. Features sunset based on data, not just features added. And cost-per-feature in production, because the AI-era product audit isn’t just “is this used?”, it’s “is this used enough to justify what it costs us to keep running?”
Tying all of this together: value density
A note before we leave business models. There’s a principle running underneath all three shifts above, and it’s worth naming.
Ben Murray, the SaaS CFO, said it cleanly: “If SaaS is about margin efficiency, AI is about value density. You’re optimising for how much output, productivity, or labor you replace per dollar of compute.”
That’s the new unit economics question, and it’s measurable. The numbers are already showing up in the data. ICONIQ’s January 2026 State of AI report puts inference at 23% of revenue for scaling-stage AI B2B companies. That same report shows AI gross margins averaging 52% in 2026, up from 41% in 2024 but still well below the 70-90% that mature SaaS companies hit. Bessemer pegs AI-first companies at 50-60% gross margins. Jason Lemkin’s framing: “as you grow, you need ever more inference. You can’t cut it without degrading the product.”
So how do you actually measure value density? It’s not one ratio. It’s three, and they move independently.
Cost-to-deliver per task. What does it cost you, in tokens and compute, to produce a successful output? This is the bottom of your funnel. If you can’t answer this, you can’t answer anything else.
Revenue captured per dollar of compute. Are you charging enough to cover variable cost plus margin? A flat-rate plan with a power user can mean negative revenue per dollar of compute on that account.
Value delivered to the user per dollar of compute. This is the one most teams skip. Did the user get something worth what you spent? A team can be strong on the first two ratios and still build a product nobody wants to pay more for. A team can be strong on the third and have terrible economics. The diagnostic only works if you measure all three.
The future: humans receding from the loop
Business models are getting way more complex. But products still have to drive them. That’s a Lean Analytics principle that hasn’t moved an inch.
What has moved is what a “product” even is, and who (or what) is using it. The thread running through everything below is the same shift viewed at four different distances. The human is receding from the loop. Still building. Still using. Still paying. But increasingly through, behind, or alongside agents that decide what actually happens.
Build-too-much is the new overfitting
Building is so easy now that the risk is shipping more than users can absorb, or more than your data can tell you is actually right. Every feature has a cost (cognitive, operational, and literal), but when the cost of adding one drops to nearly zero, the urge to ship everything is hard to resist.
Alistair wrote about this exact problem from the engineering side:
Fallbacks and the deletion problem
In “Fallbacks will be the death of us,” Alistair argues that AI removes the friction that used to force deletion. Old code stayed because rewriting was expensive. Old features stayed because building was costly. Friction was the garbage collector.
Now that building is cheap, nothing gets pruned. Fallbacks pile up into “invisible load-bearing walls.” Tests become dishonest (AI-generated tests often optimize to pass themselves rather than to validate the desired behavior). The whole system bloats silently.
He wrote, “deletion feels riskier than retention, and without friction, things stay.”
PMs need to own this. If nobody on your team is saying “this has to go,” you’re accumulating debt that’s hidden from your own metrics. Worse, as Alistair notes, you can’t trust your regression suite either, because the AI wrote the tests and the AI is grading the tests. Go read it.
The PMs who resist build-too-much and learn to measure deletion as carefully as they measure addition will win.
Agents as users
When a Claude agent uses your product on behalf of a human who never sees your UI, who is the user? What does “activation” even mean? What’s session length? What counts as engagement when the thing using your product has no attention, no fatigue, and no churn risk?
I don’t fully know. I’m not sure anyone else does yet either.
What I do know: if you’re not instrumenting agent traffic as a separate cohort today, you’ll miss the shift when it happens. And it’s going to happen.
The practical move is to start capturing user-agent strings, API patterns, and anything else that helps you distinguish “human driving the UI” from “agent hitting the API.” Track them as separate funnels. The behavior is different, the success criteria are different, and mixing them into one metric is going to give you the wrong answer on both.
Sidebar: Rob May on why HX replaces UX
Rob May recently wrote a piece worth reading: “The End of The Funnel: Why HX Is The Next Big Design and Investment Frontier.”
His argument: thirty years of UX has been about getting humans to click the right button. Conversion funnels. Onboarding flows. A/B tests on button color. When an autonomous agent books your flight, it skips all of that. It hits an API and returns a result.
His line: “The funnel isn’t just broken. It’s irrelevant.”
What replaces it is what Rob calls HX, or Harness Experience. The metaphor is deliberate. You don’t operate a harness, you wear one. It distributes load, keeps you tied to something powerful, and lets you stay in control without doing all the work yourself. HX is the design layer for a human who is steering, trusting, and auditing a fleet of agents working on their behalf. The user becomes a director, not a driver, and the metrics shift accordingly. You stop measuring clicks and conversions. You start measuring outcomes, oversight, and intervention.
If you want a sharper mental model for what “agents as users” actually means in practice, Rob’s piece is the best one I’ve read on it.
Discoverability and reuse
Two problems, one root cause: an AI that isn’t yours decides whether your product gets used.
Discoverability is the obvious one. A user opens ChatGPT and says “help me plan a trip to Mexico.” ChatGPT decides whether to invoke Expedia, Booking, Kayak, a niche specialist, or none of the above. The user never picked a tool. The AI did. For thirty years, distribution was about getting a human to find and choose you. In an agentic world, the human delegates the choice, and you’re competing for the AI’s selection logic, not the human’s attention.
Reuse is the one most teams haven’t grappled with yet, and it’s the more unsettling of the two. A user signs up and pays for Canva. They have the Canva ChatGPT app installed. Then they ask ChatGPT to help design something. ChatGPT still decides whether to invoke Canva. The user already chose. The user already paid. The AI gets to override that choice every single time the user goes through the AI to get work done, unless the user explicitly asks.
Same dynamic with Claude skills. You install a skill, you can be explicit about when to use it, or Claude decides. As more work routes through AI assistants, the AI becomes the gatekeeper not just for acquisition but for reuse of tools you already own. Owning the customer doesn’t mean owning the moments where the customer actually gets value. That’s a new kind of platform risk, and most teams haven’t priced it in yet.
What to start tracking: the gap between “users who own or pay for the product” and “users where the AI actually invoked it when it could have.” A paying subscriber whose AI hasn’t invoked them in 30 days is more at risk than a subscriber who hasn’t logged in directly. The first one might never log in directly again. They might just talk to ChatGPT. And the AI may have quietly stopped picking you.
Agent-to-agent products
When your product is a network of agents collaborating with other people’s agents, what’s the OMTM? What’s stickiness? What’s churn?
We don’t fully know. But the PMs thinking hard about these questions in 2026 will write the next version of the book.
If you remember Shift 2 for product metrics, I leaned on Nir Eyal’s Hooked as the dominant mental model for product loops. Trigger, action, reward, investment. Every single phase of the classic Hook Model has to be reconsidered when humans are receding from the loop.
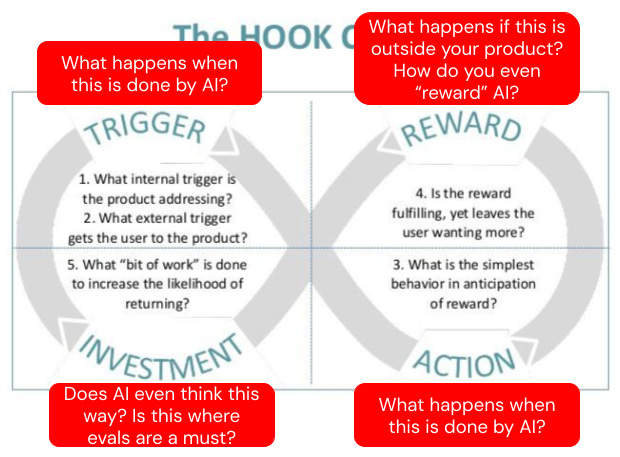
The four phases are still there. Each one now has a question on it that didn’t exist five years ago. What does a trigger mean when the AI is doing the triggering? What’s an action when the AI takes it? How do you reward something that doesn’t experience reward? Does investment apply to a system that has no memory of previous loops, or has perfect memory of every loop it’s ever been part of?
The PMs that figure this out will lead the way. They’ll build new products and experiences for AI-”users” and simultaneously figure out what to measure to learn if they’re heading in the right direction.
What to actually start doing today
The Lean Analytics frameworks still work. Know your stage. Know your model. Pick the one metric that matters. Draw a line in the sand.
The specific metrics you inherited from the SaaS playbook need a rewrite. Time-to-value collapsed. Engagement is directional. Stickiness is trust. Quality is a cohort, not a property. Your power users might be your biggest unit-economic hole.
Here’s what I’d do, concretely, starting today:
Audit your engagement metrics. Stop asking "is engagement up or down?" and start asking "what is the user's time being spent on?" Time spent struggling is failure dressed as engagement. Time spent with the AI doing the work on the user's behalf is real value. The number on the dashboard is the same in both cases: your job is to know which one you're looking at. Get this wrong and you'll spend the next quarter optimizing for failure.
Add a quality-by-cohort view. Measure output quality for new users separately from power users. The gap might be bigger than you expect, and it tells you exactly where onboarding has to get better.
Look at gross margin per active user. Not per paying user. Per active user. Your best users are either your best asset or your biggest liability, and your current dashboard probably doesn’t tell you which.
Start instrumenting agent traffic separately. Even if it’s 2% today. It won’t be for long, and you’ll want the baseline before the shape of your traffic changes.
Build an eval harness. Alistair is right. If you can’t systematically evaluate whether your AI is doing the thing you want it to do, you don’t have a product. You have vibes.
Evaluate how you build features. Are you running tight experiments, or vibe-stuffing your product to death? How efficient and effective are your teams?
The book still holds up. The lens has shifted.
How are you handling the shifts in product, business models and metrics being created by AI?